Using Consumer Priorities with RabbitMQ
· 4 min read
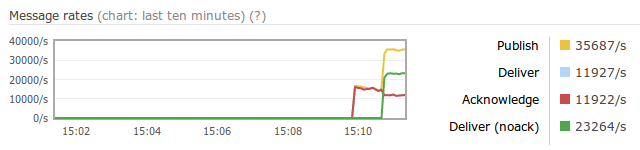
With RabbitMQ 3.2.0 we introduced Consumer Priorities which not surprisingly allows us to set priorities for our consumers. This provides us with a bit of control over how RabbitMQ will deliver messages to consumers in order to obtain a different kind of scheduling that might be beneficial for our application.
When would you want to use Consumer Priorities in your code?